overleaf template galleryLaTeX templates and examples — Recent
Discover LaTeX templates and examples to help with everything from writing a journal article to using a specific LaTeX package.

Formal letter according to SINTEF template This template is consistent with the model distributed by SINTEF as of June 2026; for more information on these classes, contact the internal SINTeX channel.

Beamer presentation style for the research institution SINTEF, 2026 version. This template is consistent with the model distributed by SINTEF as of June 2026; for more information on these classes, contact the internal SINTeX channel.

Project amendment proposal according to SINTEF template This template is consistent with the model distributed by SINTEF as of June 2026; for more information on these classes, contact the internal SINTeX channel.
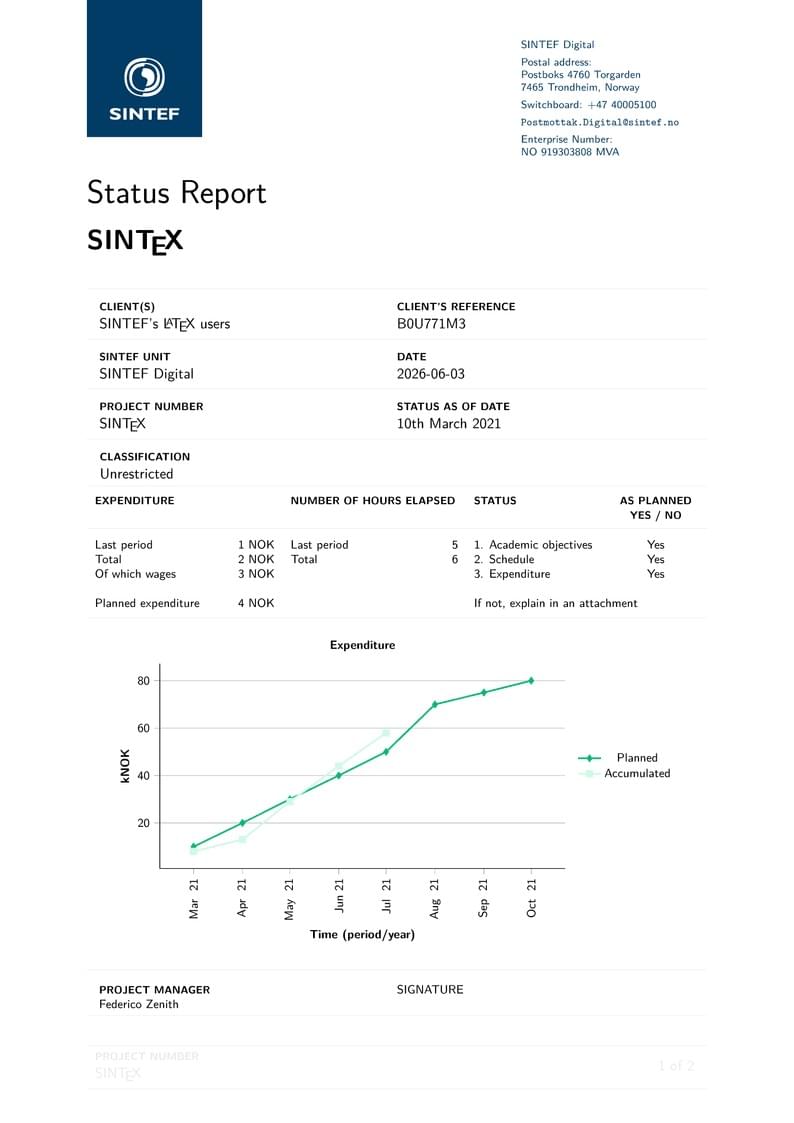
Report of project progress according to SINTEF template This template is consistent with the model distributed by SINTEF as of June 2026; for more information on these classes, contact the internal SINTeX channel.

Report of a technical test according to SINTEF template This template is consistent with the model distributed by SINTEF as of June 2026; for more information on these classes, contact the internal SINTeX channel.
Project report according to SINTEF template This template is consistent with the model distributed by SINTEF as of June 2026; for more information on these classes, contact the internal SINTeX channel.

Template for SINTEF-themed scientific poster This template is consistent with the model distributed by SINTEF as of June 2026; for more information on these classes, contact the internal SINTeX channel.

Project memo according to SINTEF template This template is consistent with the model distributed by SINTEF as of June 2026; for more information on these classes, contact the internal SINTeX channel.

Generic memo according to SINTEF template This template is consistent with the model distributed by SINTEF as of June 2026; for more information on these classes, contact the internal SINTeX channel.
\begin
Discover why over 25 million people worldwide trust Overleaf with their work.